Callback Based Async Architecture
- Differences Between Blocking Versus Non-Blocking Systems
- Callback based Async Architecture
- Links
- References
Differences Between Blocking Versus Non-Blocking Systems
Blocking Based System:
Servlet Stack 기반의 Framework 는 Blocking 방식으로 동작한다. 요청 스레드를 Blocking 하는 시스템 아키텍처를 보통 Multithreaded System Architecture 라고 부르기도 한다. Blocking 방식에서는 요청마다 스레드가 생성된다. 한정된 스레드를 효율적으로 사용하기 위해 Thread Pool 을 사용하긴 하지만, latency increases, device retries due to errors 등으로 인해 active connection 및 스레드 수가 증가할 수 있다. 이 경우 스레드가 서버 부하를 급증시켜서 문제가 발생할 수 있다.
처리량과 성능 측면에서 Reactive Stack 에 밀릴 수 있다는 단점이 있지만 (사실 대부분의 경우에는 성능때문에 Reactive 로 바꿀일이 있나 싶긴하다.) Blocking 방식의 시스템은 막강한 장점이 있다. 요청과 응답 흐름을 이해하기 쉽고, 디버깅하기 쉬우며 스레드의 스택은 요청 또는 생성된 작업의 진행 상황을 정확하게 스냅샷(snapshots) 으로 표시한다.
NonBlocking Based System:
EventLoop 와 Callback 기반인 NonBlocking Systems 은 요청마다 스레드를 생성하는 것이 아니라, 일반적으로 CPU 코어당 하나의 스레드가 모든 요청과 응답을 처리 하는 방식으로 동작한다. CPU 코어당 1~2개의 스레드로 모든 요청을 처리하기 때문에 스레드가 Block 되어서는 안된다. backend latency and “retry storms” 에도 대기열 이벤트가 증가하는 것이 스레드가 쌓이는 것보다는 훨씬 저렴하다.
단점으로는 디버깅이 어려우며 Distributed Tracing 을 신경써야 한다. 다양한 비동기 라이브러리를 사용하여 코딩하는 경우 Flatmap Hell 또는 Subscribe Hell 을 주의해야 한다. 요즘에는 Backend 진영에서 Kotlin 이 거의 주 스택을 이루고 있어서 Coroutines 을 활용하면 위 문제는 해결된다.
Callback based Async Architecture
일반적으로 Callback 기반으로 요청 응답이 이뤄지는 시스템은 Async 하다. 또한 최종 응답을 수신하기 위한 Callback Endpoint 를 미리 등록 요청 해야 한다. (Callback 대신 Kafka 와 같은 Distributed Event Streaming Platform 을 사용할 수도 있다.)
Callback Based Flow:
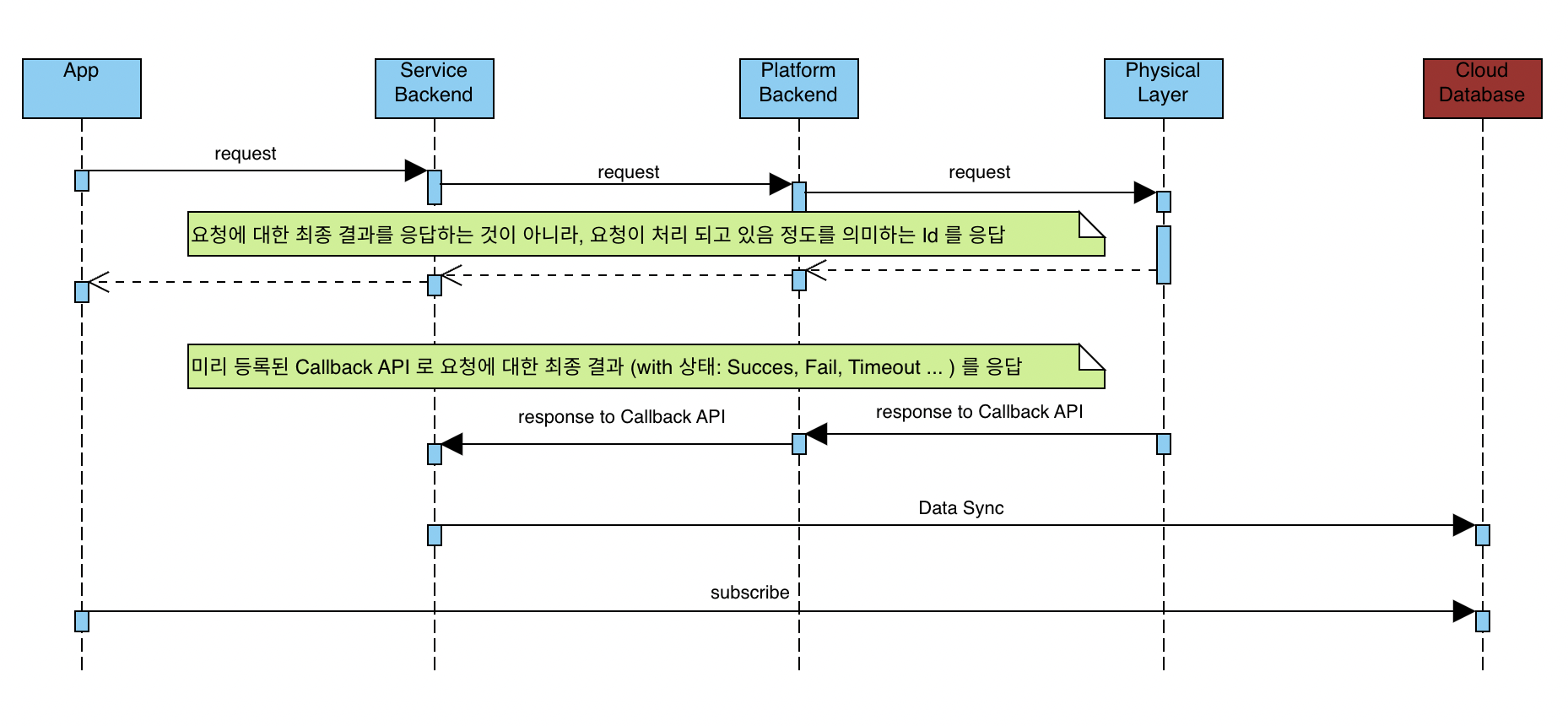
만약 App 으로 부터의 요청을 처리하기 위한 과정이 내부적으로 여러 서버, 단말 등을 거쳐야 하는 경우 가장 밑단의 아키텍처가 Callback 기반으로 Async 하게 설계되어 있으면, 윗단의 각 서비스들도 Async 구조를 따를 수 밖에 없다. (그림에서 Cloud Database 는 Firestore, Orda 등 실시간 동기화를 위한 NoSQL 기반의 실시간 Cloud Database 를 의미한다.)
이러한 Callback 기반의 Async 한 시스템에서는 앱은 요청 후 응답을 Cloud Database 의 변경 Event 를 통해 받아야 한다. 만약 Timeout 등 문제가 있을 수 있으니, 요청 후 응답을 받기 까지 Loading Progress 정책 등도 같이 고려가 되어야 한다.
Async System 이지만, App 은 요청을 보내고 그에 대한 최종 응답을 Cloud Database 가 아닌 API 요청 결과로 받길 원할 수 있다. 이 경우 Redis Pub/Sub Messaging 을 사용하면 해결할 수 있다. Reactive Stack 인 경우에는 Reactive Message Listener 를 사용해야 한다. Kotlin 을 사용 중이라면 비동기적으로 결과를 반환 받기 위해 CompletableDeferred 를 사용할 수 있다.
Request Storms
App 에서 사용자가 클릭을 계속 하게 되는 경우, 문제가 발생할 수 있기 때문에 이에 대한 대비책을 세워야 한다. 물론 모든 아키텍처마다 적용되어야 하는 것은 아니지만, 일반적으로 적용하면 좋다. (e.g 명령을 한 번에 하나씩만 처리할 수 있는 경우 TESLA Vehicle Control 을 생각해보면 이해가 쉬울 것 같다.) 가장 쉽게 적용할 수 있는 방법은 Rate Limit 이다. 또한 Lock, Cache 등을 생각할 수 있다.
하지만 Lock 의 경우 waitTime, leasTime 에 의존적이라는 단점이 있고 상품 재고 감소와 같이 DB 에 대한 강력한 정합성을 요구하는 서비스가 아니라면 Lock 대신 Cache 를 통해 해결할 수 있다.
Request Storms Block with Caching:
- App 으로 부터 Globally Unique 한 Identifier 를 포함하여 요청을 받는다.
- Service Backend 에서 Identifier 를 Key 로 하고 Value 로는 적당한 값을 넣어 캐싱한다.
- Service Backend 에서 Platform Backend 로 요청을 보내고, 응답을 받는다.
- 이때 에러 응답을 받으면 Cache 를 삭제한다.
- 미리 등록된 Callback API 로 최종 응답을 받게 되면, 응답에 담겨져 있는 상태를 확인하여 Redis Channel 로 Publish 한다.
- 1번 요청을 처리하는 도메인 메서드에서 Subscribe 하여 Cache 를 삭제한다.
- Success 인 경우 삭제
- Timeout, Fail 등 인 경우 삭제
이러한 "하나의 명령을 처리하기 까지 다른 명령은 수행할 수 없다" 라는 Transaction 을 처리하기 위해서 Cache Set/Delete 를 한 번더 Abstraction 시켜, Readability 를 높일 수 있다.
Abstracted By Cache Set/Delete Mechanism:
class CommandTx {
fun start() {
// cache set
}
fun rollback() {
// cache delete
}
}
Links
- Zuul 2 : The Netflix Journey to Asynchronous, Non-Blocking Systems
- Blocking NonBlocking Synchronous Asynchronous
References
- Design Patterns for Cloud Native Applications / Kasun Indrasiri, Sriskandarajah Suhothayan Author / O'REILLY